QuickML and Zia for Personalized Customer Experiences at Scale
Inside the Cookbook
- QuickML features across the ML lifecycle
- Data preprocessing
- Machine learning algorithms
- LLM serving with QuickML
- RAG in QuickML – one-click setup
- Zia: Your Intelligent AI Assistant
- Key Zia services in Catalyst
- Final thoughts
QuickML features across the ML lifecycle
QuickML is Catalyst’s no-code machine learning (ML) pipeline builder with built-in Gen AI capabilities, including LLM serving and RAG. Its drag-and-drop interface streamlines every part of the ML lifecycle, from preprocessing to deployment and monitoring, making model building both accessible and scalable.
Data preprocessing
QuickML simplifies preparing data for modeling with fully no-code, drag-and-drop features.
Data cleaning: Remove duplicates, handle missing values, and correct inconsistencies to ensure high-quality inputs.
Data transformation: Convert data into the right format, including scaling, encoding categorical variables, and generating derived features.
Data extraction: Pull relevant information from structured and unstructured sources to make it ready for model training.
Machine learning algorithms
QuickML supports a wide variety of algorithms for diverse predictive tasks.
Classification algorithms: Categorize data into predefined classes (e.g., churn prediction, spam detection).
Regression algorithms: Predict continuous values such as sales forecasting or pricing trends.
Ensembling: Combine output of multiple models to improve accuracy and robustness.
Recommendation models: Build personalized suggestions for products, content, or services.
Time series models: Analyze sequential data to forecast trends and detect anomalies.
Text analytics: Apply NLP techniques for sentiment analysis, keyword extraction, and document summarization.
LLM Serving and RAG with QuickML
QuickML now introduces two powerful new features: Large Language Model (LLM) Serving and Retrieval-Augmented Generation (RAG).These features simplify the process of working with LLMs, making it more flexible. Together, these new features help you deploy smarter, more reliable AI experiences at scale all from a single platform.
LLM serving made simple
Fine-tune responses for tone, creativity, and length.
Switch seamlessly between multiple models.
Deploy LLMs into applications via API endpoints with no complex setup.
Optimize performance and cost by reducing token usage.
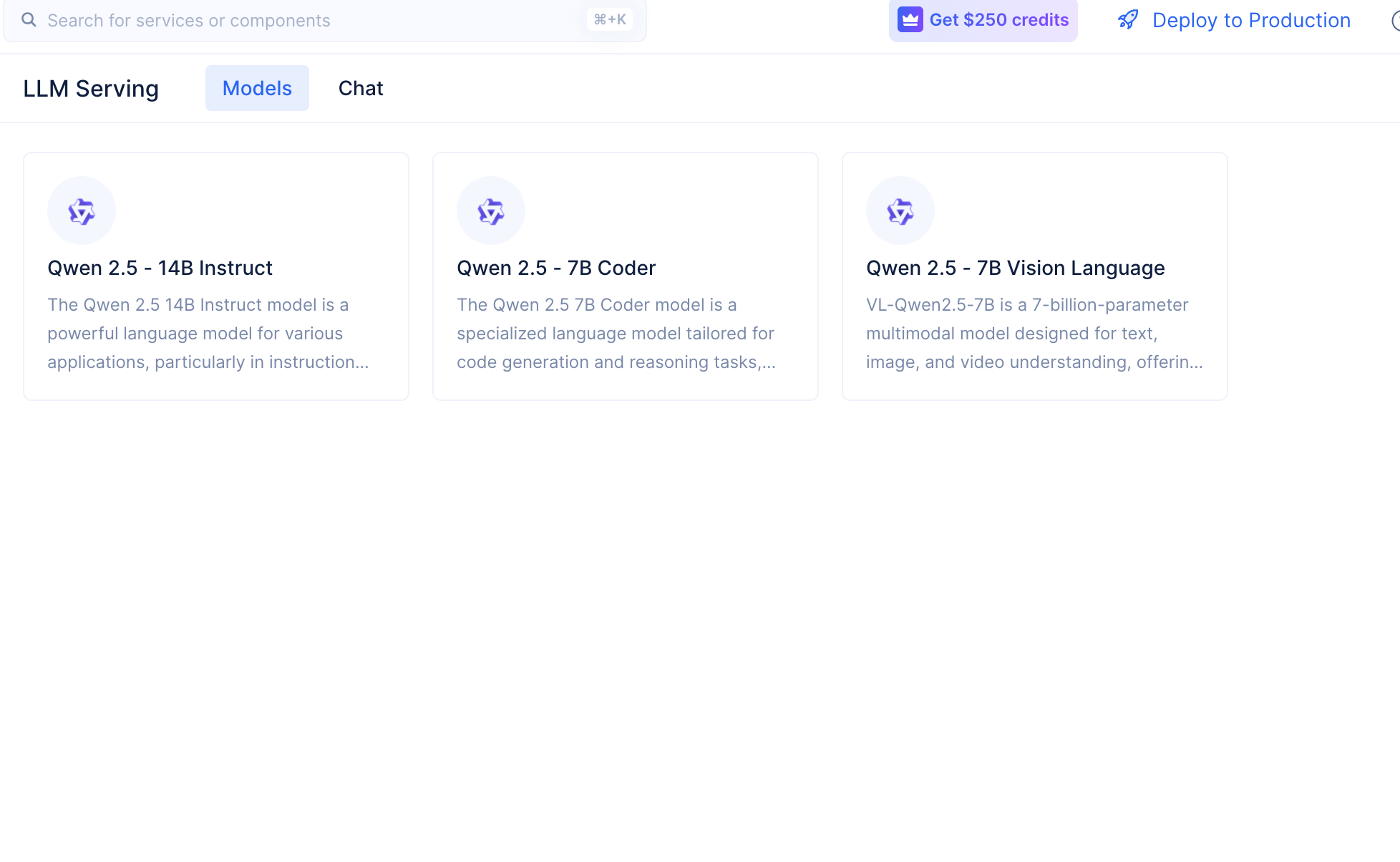
Curated models include:
Qwen 2.5-14B Instruct for general-purpose tasks.
Qwen 2.5-7B Coder for programming and debugging.
Qwen 2.5-7B Vision Language, a multi-modal model that understands both text and images.
RAG in QuickML – one-click setup
Retrieval-augmented generation enhances your LLMs by letting them pull in context-specific data from your own sources.
To build a RAG pipeline, you typically have to follow a series of steps such as:
Retrieve relevant information – Connect to your internal knowledge base, documents, PDFs, or other data sources.
Run semantic search – Locate the most relevant content.
Refine results with re-ranking – Apply semantic similarity to prioritize the most contextually accurate information.
Pass the data to the LLM and generate answers – The model combines your query with the retrieved context to deliver clear, verifiable responses.
Sample queries:
“What's our company’s return policy?”
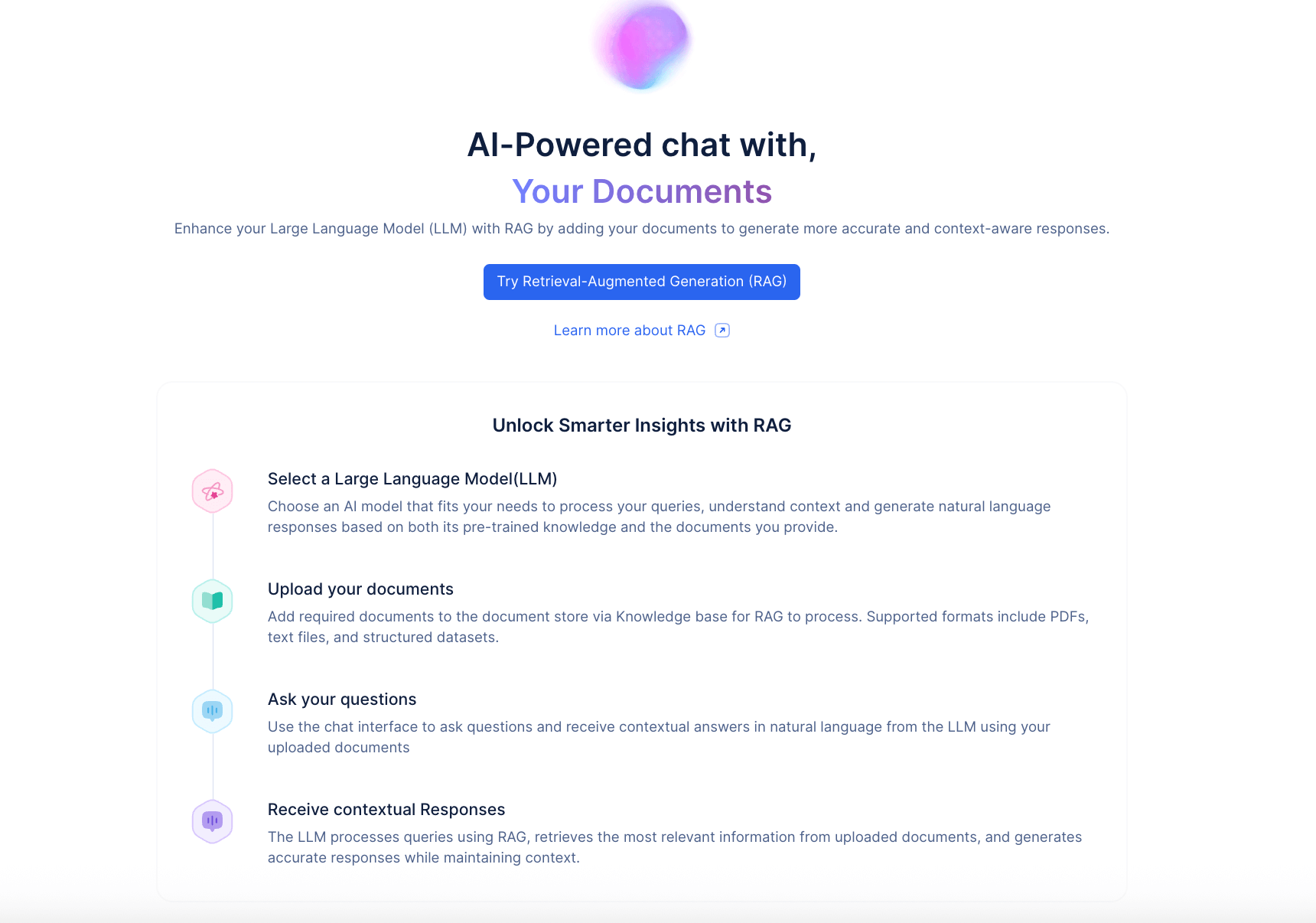
“Summarize the newest updates in our product documentation.”With QuickML, all of this complexity is abstracted away. You can launch a working RAG setup in just two steps:
Upload your documents (PDFs, Word files, text files).
Ask your questions right in the chat panel.
That’s it; you’re ready to start! No need for a vector database, manual chunking, embedding setup, or complicated pipelines. QuickML handles everything behind the scenes so you can focus on getting answers, not building infrastructure.
Note: QuickML’s RAG is currently in early access, to try RAG, reach out to us at support@zohocatalyst.com.
This means you can start asking questions and getting answers from your own data almost immediately with no extra setup.
Example queries:
“What’s our company’s return policy?”
“Summarize the latest updates in our product documentation.”
By combining LLM serving and RAG in one platform, QuickML lets you build AI-powered apps that are both intelligent and trustworthy without complex setup.
Note: RAG and LLM serving are currently in early access for requested users.
Zia: Your Intelligent AI Assistant
Catalyst Zia services is a suite of fully managed AI/ML-powered components providing predictive intelligence, analytics, and automation across applications. While QuickML focuses on ML workflows, Zia offers ready-to-use AI services to make apps smarter with minimal development effort
Key Zia services in Catalyst
Optical character recognition (OCR): Extract text from scanned documents and images.
Object detection: Identify and label objects in images.
Sentiment analysis: Understand customer emotions in feedback or conversations.
Keyword extraction: Pull important terms from text for indexing or tagging.
Final thoughts
Combining QuickML’s advanced ML capabilities like no-code ML pipelines, RAG, and LLM serving with Zia’s AI services allows businesses to embed intelligence into applications effortlessly.
From enhancing customer support and automating document processing to powering intelligent recommendations, QuickML and Zia make enterprise-grade AI accessible to everyone.
For applications that think, learn, and personalize at scale, QuickML and Zia are the go-to solutions.