What is retrieval-augmented generation (RAG)
Inside the Cookbook
- How RAG works
- Why does creating a RAG system take so long?
- QuickML makes RAG simple: One-click setup
- QuickML’s RAG: What makes it unique?
- What makes Qwen 2.5 14B Instruct powerful?
- Model details and API access
- Understanding the QuickML RAG interface
- Integrating RAG into applications
What if your AI assistant could read hundreds of pages of product documentation in seconds and give customers the exact solution they need?
Imagine this: When a customer reports a critical issue, even your most experienced support agent has to flip through those manuals to find the right fix.
Now, what if AI could do that for you instantly? What if it could scan all your documentation at once, pick out the exact answer, and respond to the customer accurately and in seconds?
That’s exactly what retrieval-augmented generation (RAG) makes possible. By combining the language generation power of LLMs with real-time retrieval from your own knowledge sources, RAG ensures your AI assistant delivers reliable, context-specific, and up-to-date answers every time.
Why LLMs need RAG
Large language models (LLMs) are incredibly powerful. Built on advanced neural networks with billions of parameters, they can understand and generate human-like text across countless topics. But there’s a limitation you can’t ignore: they are dependent on the training data.
Curious how AI systems can “search” and return the most relevant, up-to-date answers?
Behind the scenes lies Retrieval-Augmented Generation (RAG).
RAG enhances LLMs by fetching the most relevant, real-time content from trusted sources like internal documentation, product manuals, or domain-specific databases before generating a response. This means your answers are accurate, contextual, and up to date, not just limited to what the model learned during training.

How RAG works
Here’s the step-by-step flow of how RAG works.
User query: A user asks a question, e.g., “What is our company’s return policy?”
Retrieval: The system uses semantic search and embeddings to fetch the top-k relevant documents from an external knowledge base.
Re-ranking: The retrieved documents are ranked based on contextual relevance.
Augment & generate: These documents are combined with the original query and passed to the LLM.
Response generation: The LLM generates an informed answer, grounded in the retrieved context.
Citation & transparency: The model can show exactly which documents and sections were referenced.

Why does creating a RAG system take so long?
To build a RAG pipeline from scratch, you normally have to go through multiple steps:
Load the source document
Import a PDF, such as a company report, technical manual, or compliance document.Chunk the content
Break the text into smaller, manageable pieces (chunks) for efficient processing and retrieval.Maintain a vector database
Store these chunks in a vector database and handle the infrastructure for it. You’ll also need MLOps to keep embeddings updated and the database optimized.Generate and manage embeddings
Convert both the text chunks and user queries into embeddings, and ensure continuous updates for accuracy as data changes.Retrieve relevant chunks
Use similarity search algorithms to fetch the most relevant pieces of content in real time.Host and scale the LLM
Deploy your large language model, ensure it’s optimized for performance, and manage auto-scaling to handle multiple queries without latency issues.Generate a context-aware response
Provide the retrieved chunks to the LLM, which then crafts a factual and contextually accurate answer.
QuickML makes RAG simple: One-click setup
With QuickML, you don’t need to worry about these steps. Instead, you can build a fully functional RAG system in just two steps:
Upload your documents (PDFs, Word files, text files).
Ask your questions directly in the chat panel.
That’s it, you’re ready to go! No need for a vector database, no manual chunking, no embeddings setup, no complex pipeline. QuickML handles it all behind the scenes, so you can focus on getting answers, not building infrastructure.

QuickML’s RAG: What makes it unique?
QuickML brings RAG into the enterprise with advanced features, deep Zoho integrations, and complete transparency.
The response breakdown panel: Shows the specific content snippets referenced during answer generation, along with their corresponding sources and document IDs.
Zoho ecosystem integration: Import documents seamlessly from WorkDrive and Zoho Learn into the knowledge base.
Enterprise-ready LLM: Powered by Qwen 2.5 14B Instruct, QuickML ensures accurate, context-aware responses.
Flexible upload options: Add documents from desktop, WorkDrive, or Zoho Learn links.
File support: Upload PDFs, Word docs, and text files.
What makes Qwen 2.5 14B Instruct powerful?
Model size: 14 billion parameters for deep comprehension and natural language generation.
Training size: Trained on 18 trillion tokens, ensuring extensive domain coverage.
Context length: Supports 128K input tokens, ideal for long documents and in-depth context.
Adaptability: Handles dynamic real-world scenarios, making it perfect for production use.
Model details and API access
To view the model’s details:
Go to the RAG tab and click View API in the top-right corner of the chat interface.
The details include:
Endpoint URL - Used to send API requests.
OAuth Scope:QuickML.deployment.READ for secure access.
Authentication - OAuth for identity verification.
HTTP method - POST for all API calls.
Headers - Include metadata and authorization token.
Sample request & response - JSON format for input prompts and the model’s grounded output.
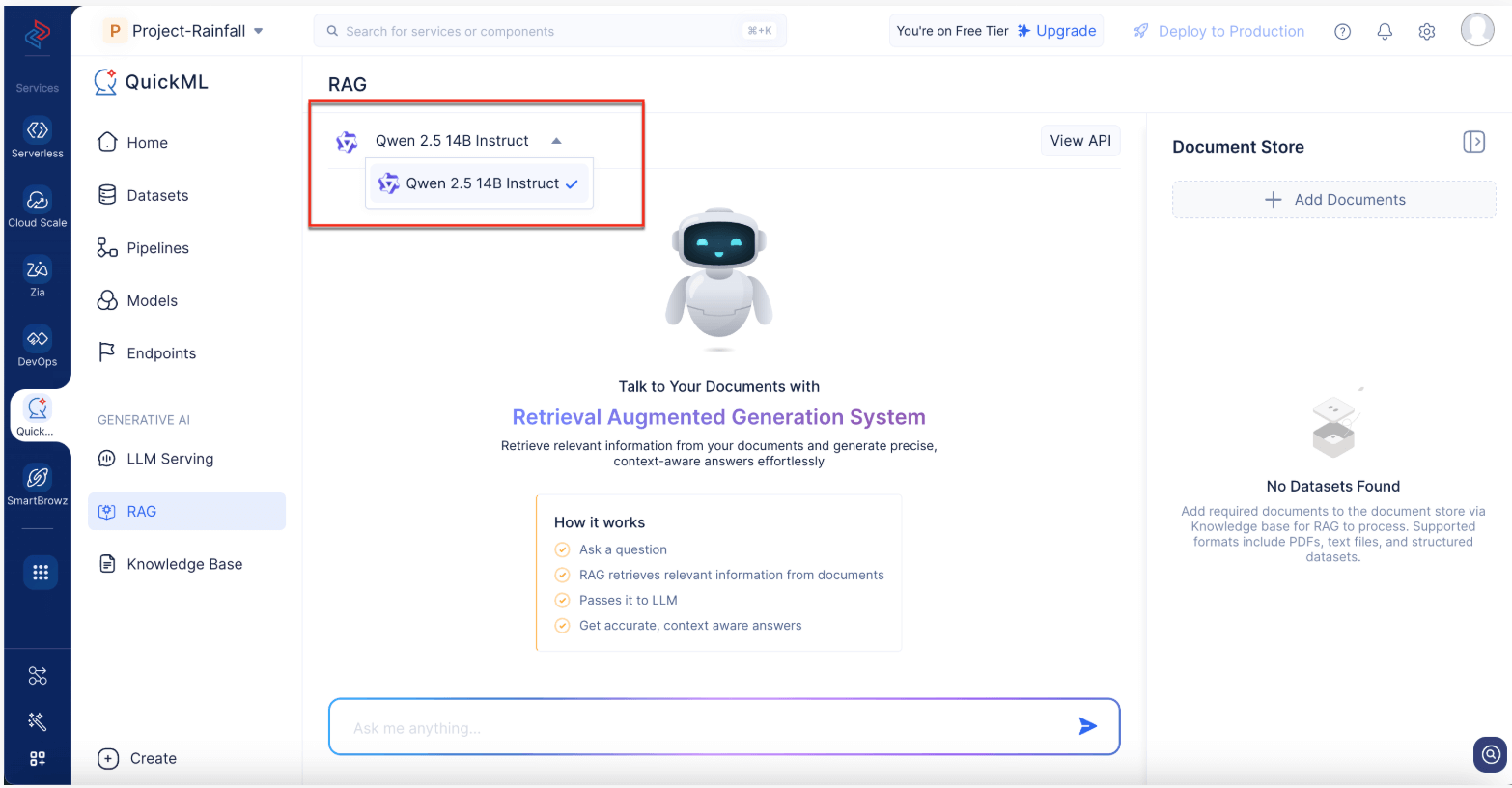
Understanding the QuickML RAG interface
Model selection: Choose Qwen 2.5 14B Instruct from the top of the chat panel.
Chat panel: Enter queries and view responses with action icons for copying or regenerating answers.
Response breakdown panel: Click View Response Breakdown to see referenced documents and sections.
Document store: Manage your uploaded documents, delete old files, or add new ones from the knowledge base.
Upload options: Desktop (.pdf, .docx, .txt),Zoho WorkDrive,Zoho Learn links
Integrating RAG into applications
QuickML provides API endpoints for integrating RAG into your chatbots, knowledge assistants, or enterprise apps. OAuth authentication ensures security during API calls. QuickML RAG Help Doc
QuickML’s RAG is currently in early access. If you want to explore context-aware AI with document-based answers, submit your request today and stay ahead with AI that retrieves, reasons, and responds accurately.
Ready to try RAG? Reach out to us at support@zohocatalyst.com